
Введение
Обнаружение злонамеренных действий осуществляется путём сбора биометрической базы данных Умного здания на основе IoT. Функции обработанных биометрических данных извлекаются для анализа с использованием основных компонентов ядра системы. Затем обработанные биометрические признаки классифицируются с помощью свёрточной нейросети VGG 16. Затем вся сеть защищается с помощью протокола детерминированной доверительной передачи (DTTP). Производительность предложенного метода рассчитывалась с использованием нескольких показателей, таких как точность (f-оценка), полнота и среднеквадратическая ошибка. Результаты моделирования показали, что предложенный метод обеспечивает лучшие результаты обнаружения вторжений.Биоидентификация с применением ИИ
Современные методы биометрической аутентификации пользователей должны обладать высокой точностью, универсальностью и высокой производительностью (практически в реальном времени). Биометрическая аутентификация подразделяется на две категории: физическая и поведенческая. Физическая биометрия основывается на определённых индивидуальных физических характеристиках людей и сочетает в себе следующие методы: сканирование лица, рисунка вен ладоней, голоса, радужной оболочки глаза и отпечатков пальцев. Поведенческая биометрия работает исходя из того, что поведение человека при выполнении определённых задач обычно достаточно отчётливо повторяется, чтобы его можно было использовать для аутентификации пользователя. В качестве примера можно привести динамику касания сенсорного экрана смартфона, нажатия клавиш клавиатуры и динамику движения и кликов мыши. Если сравнивать поведенческую биометрию с физической биометрией для аутентификации, поведенческая биометрия привлекла больше внимания из-за её более широкой применимости, меньшей навязчивости и отсутствия внешних датчиков. Кроме того, было продемонстрировано, что динамика мыши является непрерывным, портативным и ненавязчивым решением для аутентификации пользователя. Кроме того, методы машинного обучения (ML) и глубокого обучения (DL) могут извлечь выгоду из огромных объёмов данных динамики движения мыши, доступных в доменном пространстве. Когда методы ML и DL объединяются, работа с большим количеством данных показывает удивительные результаты. ML оказалось достаточно сильным, чтобы его можно было применять к различным проблемным областям, и использует неявные шаблоны на больших объёмах данных, которые слишком сложны для восприятия людьми. Тем не менее этот метод всё же требует большого ручного труда для извлечения нужных признаков из большого количества данных. Найти наилучшее сочетание гиперпараметров, извлекаемых функций и методов подготовки данных для конкретной задачи очень сложно. Аутентификация с помощью ИИ может решать ряд задач в сочетании с машинным обучением и глубокими нейронными сетями. Рассмотрим текущее состояние аутентификации с применением ИИ. Аутентификация с использованием связки логина и пароля больше не являются единственным методом аутентификации. ИИ успешно работает с распознаванием изображений, таких как отпечатки пальцев, рисунки вен ладоней и распознавание лиц, а также хорошо верифицирует пользователей по динамике нажатия клавиш и движения мыши.Важным шагом в развитии биометрической идентификации является решение о том, какие данные следует комбинировать и как их комбинировать. На данный момент исследователи предложили большое количество мультибиометрических комбинаций. В мультимодальных методах биометрического распознавания, использующих два подхода на уровне признаков: первый – оптимизация по алгоритму светлячков, а второй – сочетание теории фракталов и алгоритма светлячков, также для выполнения предварительной обработки применяется метод быстрого преобразования Фурье (FFF) и метод опорных векторов (SVM). В последние годы эта тенденция была определяющей, а методы аутентификации с помощью ИИ лидируют с точки зрения безопасности и совместимости с максимально возможным количеством реальных систем.
Рассмотрим метод безопасной передачи данных и обнаружение злоумышленников в системе биометрической аутентификации. Новый метод безопасной передачи данных при биометрической аутентификации основан на технологиях извлечения признаков с последующей их классификацией. Здесь злоумышленник обнаруживается путём сбора биометрической базы данных умного здания на основе IoT. Функции обработанных данных извлекаются с помощью анализа основных компонентов на основе ядра (KPCA). Затем обработанные признаки классифицируются с использованием свёрточной архитектуры VGG 16. Затем вся сеть защищается с помощью протокола детерминированной доверительной передачи (DTTP). Общая архитектура предлагаемого метода представлена на рис. 1.

Чтобы получить более точные и качественные данные, необходимо провести нормализацию данных для масштабирования характеристик, чтобы они соответствовали заданному максимальному и минимальному значению, обычно между единицей и нулем, как показано в уравнении (1). Это является одним из подходов к предварительной обработке данных.
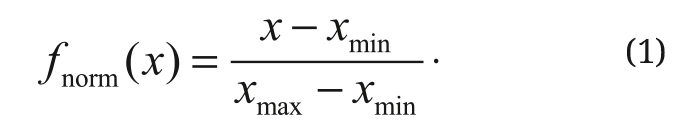
В уравнении (1) приведена техника преобразования значений (MMN, MMS) так, что они располагаются в диапазоне от 0 до 1. Далее использовалась свёрточная нейронная сеть VGG16, результаты работы которой достигают точности 92,7% в задачах распознавания объектов на изображении. Обучение модели проводилось на базе более чем 14 миллионов изображений, принадлежащих к 1000 классам. Безопасная передача данных основана на использовании протокола детерминированного доверия (DTTP). Данный протокол способствует пересылке пакетов для каждого узла с помощью комбинированных значений доверия (CTV).
Каждый сенсорный узел в предлагаемом методе имеет CTV, основанный на следующих факторах оценки доверия:
- идентификация: содержит информацию о местоположении узла, а также его идентификатор;
- чувствительность данных: этот элемент включает в себя сбор данных и определение времени события;
- согласованность: уровень согласованности узла представлен этим фактором.
С течением времени значения доверия для соседних узлов непрерывно меняются. Если узел делает несколько незначительных ошибок при приёме или передаче событий, это мало влияет на значение доверия, которое оценивают его соседи. В противном случае, если узел постоянно передаёт неточные данные или редко связывается со своими соседними узлами, его значение доверия падает и приближается к –1. В результате на этом этапе можно обнаружить и классифицировать некоторые вредоносные или скомпрометированные узлы, которые регулярно передают противоречивые или недостоверные данные.
Ниже приведён алгоритм, который демонстрирует работу безопасной передачи данных на основе DTTP.
Algorithm 1: DTTP
For every sensor node, S, I = 1, 2, . . . ,n
Calculate identification factor Idi
Calculate sensing result SR
Calculate consistency value CVi
Evaluate CTVi
End for
Select aggregator node Aj with highest CTVi
For every aggregator Aj, j = 1, 2, . . . .n
When Ai receives data packet from node Si, it measures its trust value CTVi
If CTVi < CTVi then Ai will not
aggregate packet
Else
Aj aggregates packet and increment its counter CTj as Ctj = Ctj +a
Where a is the number of packets successfully aggregated by Aj
End if
Aj produces a random hash value
[MAC (agg, Ctj]
Aj transmits [MAC (agg, Ctj] to the sink
End for
When all aggregated data from Ai reaches sink, it checks the counter value Ctj
If Ctj > Ctj , then
Aj is well behaving
Else
Aj is misbehaving
End if
Aj is prohibited from further transmissions
Для проверки надёжности предложенных алгоритмов распознавания использовались две открытые базы данных. Шаньдунский университет собрал базу данных рисунков вен фаланг пальцев (FV). Каждое изображение хранится в формате «BMP», который имеет размерность 320×240 пикселей.
Гонконгский политехнический университет собрал базу данных 3D-изображений суставов пальцев (FKP), и в эту базу данных включено 7920 фотографий, состоящих из 12 изображений указательных и средних пальцев обеих рук 165 человек. Поскольку в базе данных FKP больше участников, чем в базе данных FV, для сравнения были выбраны только 106 из них. Такой подход был необходим для слияния модальностей FV и FKP на этапе обучения и тестирования. В выбранных унимодальных и мультимодальных методах классы каждой базы данных были разделены на две отдельные подбазы данных, 60% из которых использовались для обучения, а 40% – для тестирования. После двух перекрестных проверок была рассчитана точность распознавания путём чередования обучающего и тестового изображений.
В табл. 1 и на рис. 2 показан сравнительный анализ точности между предложенными и существующими методами. В данном случае был проведён сравнительный анализ различных наборов биометрических данных на основе количества обработанных изображений. Расчёт точности выполнялся с помощью метода прогнозирования на основании технологий глубокого машинного обучения (DL). Предложенный метод достиг 96% точности для 500 изображений на основе их итераций, в то время как существующий RBM достиг 83%, а CNN достиг 90% точности.


В табл. 2 и на рис. 3 показаны различные сравнения биометрических изображений на основе наборов данных с точки зрения F-показателей. Для расчёта F-показателя количество обработанных изображений составило 500 изображений как для существующей, так и для предлагаемой методики. F-оценка показывает способность различать каждый признак независимо от других признаков. Для первого признака генерируется одна оценка, а для второго признака получается другая оценка. Однако в нём ничего не говорится о том, как эти два элемента работают вместе. Здесь вычисление F-показателя с использованием эксплуатации определило эффективность прогнозирования. Он создаётся путём рассмотрения гармонического компонента отклика и точности. Если расчётный балл равен 1, это считается отличным результатом, тогда как 0 баллов указывает на плохой результат. Фактическая отрицательная ставка не принимается во внимание F-измерениями. Предложенный метод достиг 85% F-оценки для 500 изображений на основе их итераций, в то время как существующий RBM получил 79%, а CNN – 81% F-оценки.


В табл. 3 и на рис. 4 показано сравнение расчётных значений точности биометрических данных предлагаемых и существующих методов на основе 500 изображений. Точность класса рассчитывается путём деления общего количества элементов, классифицированных как принадлежащие к положительному классу, на количество истинно положительных результатов. Вероятность состоит в том, что классификационная функция будет давать положительный показатель, если она присутствует. Предложенный метод достиг 92% точности для 500 изображений, в то время как существующий RBM получил 85%, а CNN – 89%.


В табл. 4 и на рис. 5 показан сравнительный анализ полноты, основанный на количестве изображений из набора входных данных. В этом контексте полнота описывается как отношение общего количества компонентов, которые действительно попадают в положительный класс, к нескольким истинно положительным. Процент положительных образцов, которые были правильно идентифицированы как положительные, из всех положительных образцов – это то, как оценивается полнота. Насколько хорошо метод может распознавать положительные образцы, рассчитывается по полноте. Полнота увеличивается по мере того, как определяется больше положительных образцов. В данном случае предложенный метод достиг 80% отзыва для 500 изображений на основе их итераций, в то время как существующий RBM получил 65%, а CNN достиг 72% отзыва.


В табл. 5 и на рис. 6 показан сравнительный анализ RMSE, который указывает на то, что при обработке 500 изображений произошла ошибка. При обучении моделей регрессии или временных рядов RMSE является одним из наиболее широко используемых показателей для оценки того, насколько точно модель прогнозирования предсказывает значения по сравнению с реальными или наблюдаемыми значениями. Квадратный корень MSE используется для расчёта RMSE. RMSE вычисляет изменение каждого пикселя в результате обработки. Предложенный метод достиг 46% RMSE для 500 изображений на основе их итераций, в то время как существующий RBM получил 55%, а CNN достиг 48% RMSE.


Заключение
В этом исследовании был предложен новый метод безопасной передачи данных и обнаружения злоумышленника в системе биометрической аутентификации путём извлечения признаков с классификацией. В данном методе обнаружение злоумышленника реализовано на основе собранной биометрической базы данных умного здания на основе IoT. Эти биометрические данные обрабатываются для удаления шума, сглаживания и нормализации. Функции обработанных данных извлекаются с использованием анализа основных компонентов на основе ядра (KPCA). Затем обработанные признаки были классифицированы с использованием свёрточной архитектуры сети VGG-16. Затем вся сеть была защищена с помощью протокола детерминированной доверительной передачи (DTTP). Экспериментальные результаты достигли таких параметров, как точность 96%, F-показатель 85%, точность 92%, полнота 80% и среднеквадратическая ошибка 46%. Развитием этого метода может быть использование его в облачной системе кибербезопасности. Дальнейшее развитие этого метода может быть реализовано на основе набора данных, полученных в реальном времени с повышенной точностью, с использованием технологии блокчейна и методами машинного обучения. ●Автор – сотрудник фирмы ПРОСОФТ
Телефон: (495) 234-0636
E-mail: info@prosoft.ru
Если вам понравился материал, кликните значок - вы поможете нам узнать, каким статьям и новостям следует отдавать предпочтение. Если вы хотите обсудить материал - не стесняйтесь оставлять свои комментарии : возможно, они будут полезны другим нашим читателям!





