
Введение
Биометрические характеристики на основе анализа рисунка вен являются новыми признаками, которые имеют преимущества перед другими биометрическими методами. Наиболее широко используются биометрические показатели, сформированные на основе структуры сосудистого русла вен, образованного кровеносными сосудами пальцев и рук человека. Данный метод основан на распознавании вен ладоней и пальцев рук с целью идентификации по биометрическому признаку. Для этого существуют две важные предпосылки: наличие адаптивных инструментов биометрического распознавания и наборов данных для обучения, тестирования, определения биометрических характеристик, а также инструментов для оценки эффективности распознавания. В настоящее время уже есть несколько общедоступных наборов данных рисунков пальцевых и кистевых вен, содержащих более 14 400 изображений для проведения исследований. Такой набор данных является уникальным в своём роде, поскольку изображения имеют высокое разрешение. Кроме того, это первый набор данных, в котором в качестве метаданных содержатся возраст, пол и другие биометрические данные добровольцев. Изображения были получены с использованием специально разработанного сканера рисунка вен конечностей.
Для реализации полного биометрического распознавания требуются пять основных модулей. Первый необходим для сканирования рисунка вен пальцев или кистей рук и анализа набора данных. Второй нужен для предварительной обработки с целью повышения качества картинки рисунка вен. Третий используется для создания биометрических объектов, где извлекаются векторные биометрические шаблоны, кодирующие соответствующие детали узоров вен из предварительно обработанных изображений. На следующем этапе два шаблона сравниваются друг с другом и рассчитывается качественный показатель результатов сравнения. Последний шаг – оценка эффективности, где генерируются определённые показатели производительности и графики данного алгоритма. Эти результаты являются важной частью в оценке эффективности новых алгоритмов распознавания вен и формировании отчёта о результатах распознавания и его эффективности.
У некоторых опубликованных решений для распознавания рисунка вен конечностей подходят не все наборы инструментов, а только некоторые, особенно в части извлечения и сравнения признаков. Только в одной общедоступной полнофункциональной библиотеке есть все необходимые инструменты для распознавания вен, она является частью библиотеки BOB, написанной на Python. Даже эта библиотека не содержит более современных схем распознавания вен и полного набора адаптированных алгоритмов. Хотя в Python и особенно в некоторых свободно распространяемых модулях Python присутствуют несколько операций обработки изображений, многие исследователи предпочитают MATLAB вместо других языков программирования для тестирования своих новых алгоритмов. MATLAB предоставляет большое количество готовых стандартных приложений обработки изображений, простых в использовании и отладке. Одним из них является полноценная среда распознавания вен, написанная на MATLAB с открытым исходным кодом, под названием PLUSOpenVein Toolkit. Эта среда включает в себя полный набор инструментов распознавания вен, состоящий из модулей считывания изображений, предварительной обработки, извлечения признаков, сравнения и оценки производительности. Её архитектура позволяет легко интегрировать новые алгоритмы и схемы распознавания рисунка вен, гибко комбинировать различные схемы предварительной обработки и извлечения признаков. Приложение уже имеет 11 алгоритмов для предварительной обработки изображений, а также 13 функций извлечения и сравнения наборов данных вен кистей и пальцев.
Общая архитектура PLUSOpenVein Toolkit
Общая архитектура системы распознавания вен включает её структуру и основные компоненты. На рис. 1 показана структурная схема типовой системы биометрического распознавания рисунка вен, включая биометрические шаблоны, которые сначала должны быть отсканированы с помощью биометрического устройства сканирования вен, и инструменты их распознавания.

Система распознавания вен PLUSOpenVein Toolkit состоит из модулей программного обеспечения, то есть всех компонентов и инструментов распознавания, как отдельной части, так и всей фигуры. Выполнение различных этапов обработки с помощью PLUSOpenVein Toolkit представлено на рис. 2. Все модули для распознавания вен реализованы на платформе GNU Octave.

Структура каталогов
Эта структура включает в себя целый набор инструментов распознавания вен, состоящий из модуля чтения изображений, предварительной обработки, модуля с функцией извлечения векторного изображения, сравнения и оценки производительности. Такая архитектура позволяет легко интегрировать новые схемы распознавания рисунка вен, использовать гибкие сочетания различных способов предварительной обработки в комбинации с наиболее подходящими функциями и схемами извлечения. В инструментарии уже предустановлены несколько широко используемых наборов данных рисунков вен, в то же время достаточно легко подключить новые наборы данных. Имеющиеся наборы данных содержат 11 конкретных наборов рисунков вен для предварительной обработки, а также включены 13 методик для их сравнения. Вся структура предоставляется на бесплатной основе для научно-исследовательских и некоммерческих целей.
На рис. 3 показана структурная схема модуля распознавания вен. Основной программный модуль matcher.m содержит бóльшую часть логики PLUSOpenVein Toolkit и включает в себя обработку, извлечение признаков и функции сравнения.

На самом деле matcher.m является объектом MATLAB, в котором хранятся исходные изображения, извлечённые функции, результаты сравнения. Некоторые модули схем распознавания реализованы непосредственно в matcher.m, но большинство схем вызываются как внешние функции, реализованные в отдельных файлах, собранных в следующие подкаталоги:
- Automation: несколько скриптов для пакетной обработки с автоматической проверкой настроек файлов и т.п.;
- EEREvaluation: функции для определения показателей производительности и графиков;
- FeatureExtraction: большинство локальных функций извлечения объектов;
- FeatureLevelFusion: инструменты для выполнения процедуры слияния объектов и оценки полученных результатов слияния;
- Matching: различные функции сравнения;
- Preprocessing: различные функции предварительной обработки изображений вен;
- Quality Assessment: несколько общих метрик для контроля контрастности и качества изображения вен;
- ScoreLevelFusion: инструменты и функции для упрощённого вычисления баллов;
- UtilityFunctions: несколько вспомогательных функций, например, для обработки ini-файлов, плюс индикатор процесса выполнения, построение сплайна ключевых точек и многие другие.
Каждый шаг выполнения программы можно вызвать вручную. Чтобы запустить сразу всю последовательность инструментов распознавания, включая чтение изображения вен, препроцессинг, распаковку, сравнение и определение производительности, необходимо запустить скрипт automatMatcher () с указанием пути к исходным изображениям и файлу настроек. После выполнения всех этапов отображаются результаты и вычисленные значения EER/FMR (ERR – Equal Error Rate, FMR – Fastest Medium Rare).
Интегрированные схемы распознавания вен и поддерживаемые наборы данных
Несколько файлов настроек для поддерживаемых наборов данных находятся в подкаталоге Settings. В нём есть пример файла настроек под названием settingsExample.ini, в котором перечислены все возможные параметры с краткими комментариями (за исключением параметров сторонних методов предварительной обработки, извлечения функций и сравнения). Помимо биометрической информации, получаемой непосредственно с устройства захвата, данные можно читать из файлов изображений. Обработка файлов изображений (получение всех файлов в каталоге, чтение изображений и сохранение их в массиве ячеек памяти для дальнейшего использования) выполняется в readImages.m. Анализ имён файлов
(тема, палец/ладонь и идентификатор образца) основан на регулярных выражениях. Новые наборы данных можно легко обработать путём добавления ещё одного выражения для анализа имени файла в readImages.m. Далее проводится предварительная обработка файлов изображений, например, сгруппированных по венам, – сначала индивидуальные методы, а затем и общие. Все схемы предварительной обработки можно комбинировать в любом порядке и не один раз (список методов и параметров указывается в файле настроек). Далее применяются различные методы фильтрации и улучшения изображений вен, среди которых можно отметить следующие: LeeRegion – распознавание вен с использованием выравнивания по мелким точкам и извлечённым признакам на основе локальных двоичных образов; HuangNormalise – аутентификация по вене на основе выделения базовых линий рисунка вен и их нормализации и компенсация вращения; Zhang09 и Zhao09 – улучшение изображения вен на основе комбинации методов группировки по уровню серого и кругового фильтра Габора, DTFPM – аутентификация по вене, основанная на сопоставлении устойчивых к деформации характерных точек, и многие другие методы.
По завершении фильтрации изображений проводится их сравнение с существующими шаблонами рисунков вен. Для сравнения используют различные методы, но их можно отнести к методу сравнения двоичных шаблонов и гистограмм. Очень часто для сравнения бинарных шаблонов вен используется подход, предложенный Наото Миура (Naoto Miura) [1]. Этот подход представляет собой простой метод корреляции между входным и эталонным изображением. Изображения вен пальца или ладони не полностью накладывают друг на друга, а только грубо сравнивают. При этом вращение или небольшое смещение сравниваемых изображений впоследствии компенсируются математическими методами. Таким образом вычисляется соотношение сдвига между входным и эталонным изображением, а также смещение в направлении осей X и Y относительно версии эталонного изображения. Максимальное из этих значений корреляции нормализуется, а затем используется в качестве окончательной оценки сравнения. Выходная оценка – это оценка сходства в диапазоне 0,0…0,5, где 0,5 означает идеальное совпадение. Эта схема сравнения названа методом сравнения Миура. Для сравнения гистограмм в основном используют набор характеристик, заложенных в основу метода LBP (Local Binary Pattern – распознавание вен с использованием выравнивания по мелким точкам и с выделением признаков на основе локальных двоичных образов). Но наряду с этим для сравнения используют и другие методы: измерения расстояний пересечения гистограмм, критерий хи-квадрат, расстояние Бхаттачарьи, расхождение Дженсена–Шеннона, расстояние Колмогорова–Смирнова и расхождение Кульбака–Лейблера. Можно выбрать любой из этих методов вычисления расстояния, если сравниваются не шаблоны, а гистограммы.
Протоколы сравнения и оценки качества
Чтобы рассчитать частоту ложных совпадений (FMR – False Match Rate) и частоту ложных несовпадений (FNMR – False Non Match Rate), как установлено стандартом ISO/IEC 19795-1, до определения дополнительных показателей производительности, таких как равная частота ошибок (EER), включены несколько различных протоколов. Для сравнения взят за основу протокол FVC (Fingerprint Verification Competition), поскольку он ранее уже использовался для проверки отпечатков пальцев (FVC2004). С его помощью выполняются все возможные достоверные сравнения, то есть каждый образец сравнивается со всеми оставшимися образцами того же биометрического экземпляра пальцев или ладоней. Симметричные сравнения не осуществляются, другими словами, если выполняется сравнение [изображение A – изображение B], то сравнение [изображение B – изображение A] не делается, поскольку большинство биометрических показателей симметричны, и оба сравнения приведут к одинаковому результату. Для удобства проведения сравнения каждый входной файл ладони был преобразован в модель, состоящую из следующих полей: идентификатор пользователя, идентификатор ладони, номер изображения и шаблон ладони. Сравнение проводится следующим образом: входной биометрический слепок преобразуется в модель, описанную ранее, далее из модели берётся шаблон отпечатка и сравнивается со всеми шаблонами отпечатков ладоней из эталонной выборки. В процессе сравнения используется основной параметр, называемый порогом срабатывания (Threshold). Порог срабатывания – это количество особых точек, которые должны совпасть, чтобы система решила, что рисунки вен идентичны.
В результате сравнения система возвращает ответ, который относится к одному из двух классов. Первый класс – рисунки совпадают. Ответ системы: 1. Второй класс – рисунки не совпадают. Ответ системы: 0. Далее ответ системы сравнивается с реальным значением совпадения проверенных отпечатков.
В результате конечный ответ может быть четырёх видов:
- True Positive (TP) – система дала ответ, что рисунки вен совпадают, и ладони на самом деле совпадают;
- False Positive (FP) – система дала ответ, что рисунки вен совпадают, но на самом деле они не совпадают. Ошибка первого рода;
- True Negative (TN) – система дала ответ, что рисунки вен не совпадают, и они на самом деле не совпадают;
- False Negative (FN) – система дала ответ, что рисунки вен не совпадают, а на самом деле они совпадают.
Доля ошибок первого рода (FAR – False Acceptance Rate) определяется по формуле (1). Эти ошибки происходят, когда система определяет незарегистрированного пользователя как зарегистрированного. Этот тип ошибки критичен для безопасности.

Доля ошибок второго рода (FRR – False Rejection Rate) рассчитывается по формуле (2). Этот вид ошибок происходит, когда сканер не может распознать зарегистрированного пользователя. Это не критично для безопасности, но создает неудобства, так как нужно проводить вторичную проверку биометрического параметра. Эти две характеристики являются стандартными для биометрических систем.
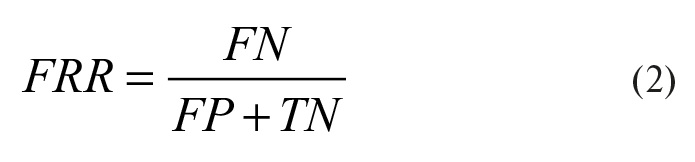
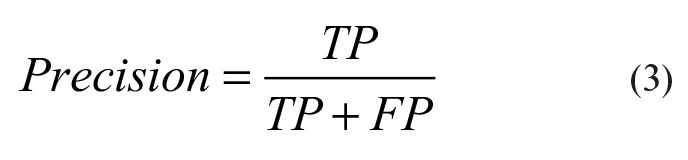
Для оценки качества работы системы в каждом из классов по отдельности введём метрики Precision (точность) и Recall (полнота). Precision (3) можно интерпретировать как долю изображений, названных системой как совпадающие, и при этом действительно совпадающих, а Recall (4) показывает, какая доля изображений из тех, которые должны были совпасть, была найдена системой. Именно введение Precision не позволяет системе записывать все изображения в один класс, так как в этом случае мы получаем рост уровня False Positive. Recall демонстрирует способность системы обнаруживать данный класс вообще, а Precision – способность отличать этот класс от других классов.
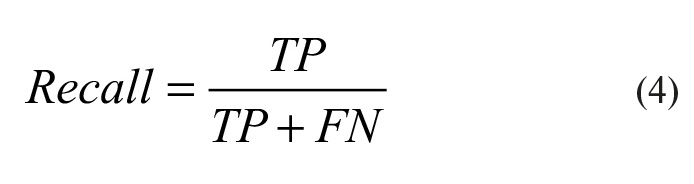
Заключение
Для проведения исследования в области распознавания вен необходимы две важные вещи: подходящий и доступный набор биометрических данных и реализация цепочки инструментов для распознавания рисунка вен, включая предварительную обработку, извлечение функций, сравнение и оценку производительности, которые представлены в PLUSOpenVein Toolkit. ●
Литература
фирмы ПРОСОФТ
Телефон: (495) 234-0636
E-mail: info@prosoft.ru
Если вам понравился материал, кликните значок - вы поможете нам узнать, каким статьям и новостям следует отдавать предпочтение. Если вы хотите обсудить материал - не стесняйтесь оставлять свои комментарии : возможно, они будут полезны другим нашим читателям!





