
Именно этой проблеме посвящён анализ вероятностной природы современных ИИ-систем. Главная идея заключается в том, что способность модели «иногда правильно отвечать» принципиально отличается от гарантированной воспроизводимой точности, необходимой для промышленного применения.
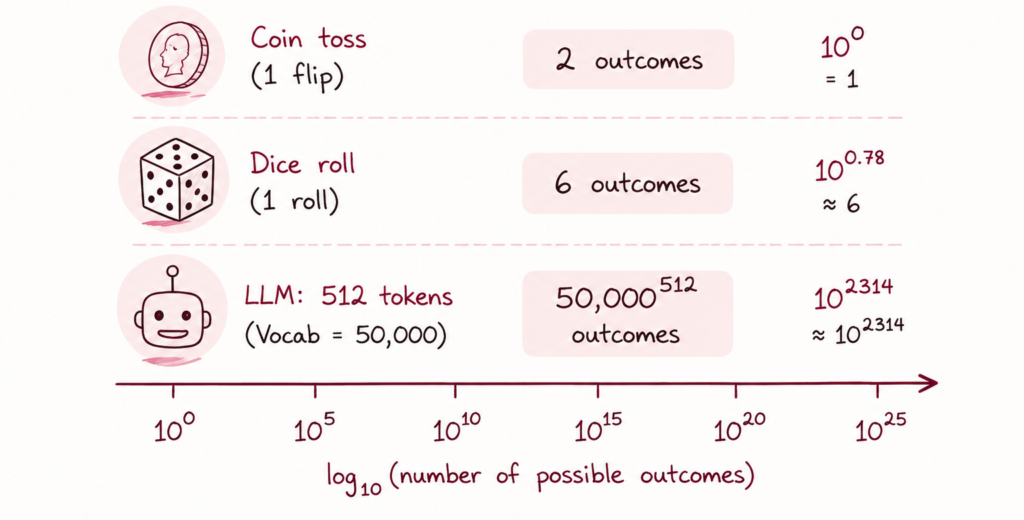
Авторы отмечают, что многие пользователи ошибочно интерпретируют возможности больших языковых моделей. Тот факт, что нейросеть способна однажды написать рабочий драйвер ядра, сгенерировать сложное изображение или решить математическую задачу, ещё не означает стабильности результата. В системах с гигантским пространством возможных ответов практически любой исход теоретически достижим — вопрос лишь в вероятности его повторения.
Для языковых моделей эта проблема особенно заметна. При генерации текста система выбирает следующий токен из огромного множества вариантов. Даже если область действительно полезных и корректных ответов существует, она может занимать лишь небольшую часть общего пространства вероятностей. Именно поэтому возникают так называемые галлюцинации — правдоподобные, но фактически неверные ответы.
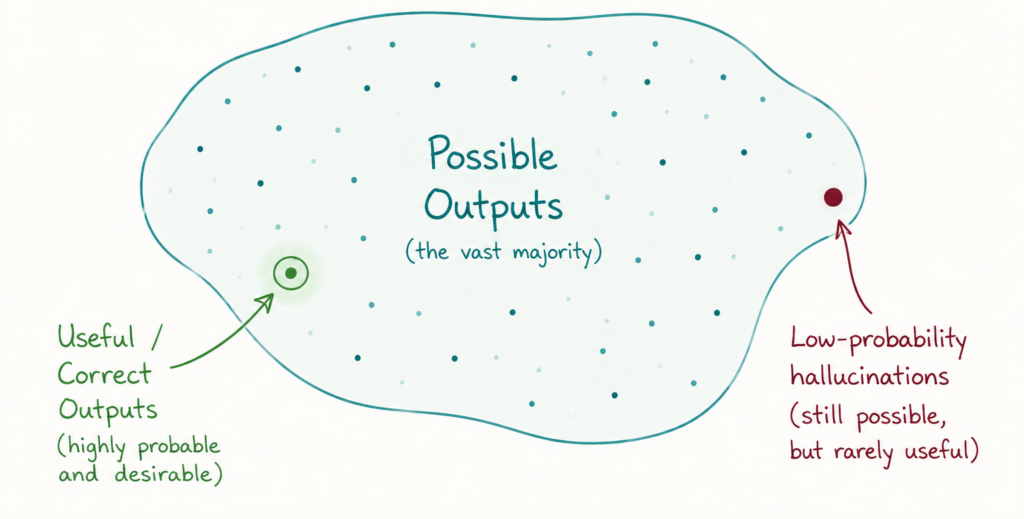
Авторы подчёркивают, что галлюцинации не являются простой программной ошибкой. Это естественное следствие работы вероятностной системы, которая периодически выбирает варианты с низкой практической ценностью, но ненулевой вероятностью появления.
Отдельное внимание уделяется проблеме «ложной уверенности» моделей. Многие современные нейросети используют функцию Softmax для оценки вероятности ответа, однако высокая уверенность системы далеко не всегда означает истинность результата. Небольшое различие между внутренними параметрами модели может экспоненциально усиливаться, создавая впечатление высокой достоверности даже при ошибочном выводе.
Ещё одна фундаментальная проблема связана с обучающими данными. В теории увеличение объёма информации должно повышать качество модели, однако человеческий язык и знания не представляют собой стабильное распределение. Они содержат противоречия, ошибки, региональные особенности и массовые заблуждения. В результате модель начинает воспроизводить не объективную истину, а статистически доминирующие шаблоны.
Авторы также ставят под сомнение популярное представление о «творчестве» генеративного ИИ. Во многих случаях необычные результаты объясняются не креативностью системы, а стохастическим выбором менее вероятных токенов при повышении параметра температуры генерации. Чем выше температура, тем больше вероятность появления неожиданных и одновременно ошибочных ответов.
На этом фоне ключевой задачей отрасли становится переход от демонстрации возможностей к созданию действительно надёжных ИИ-систем. Среди перспективных направлений называются методы калибровки доверия модели, байесовские нейросети, оценка неопределённости и внешние механизмы проверки результатов.
По мнению исследователей, будущее прикладного ИИ будет определяться уже не способностью модели «иногда впечатлять», а её умением стабильно и предсказуемо выдавать корректный результат в реальных условиях эксплуатации.Источник: https://towardsdatascience.com/from-possible-to-probable-ai-models/
Если вам понравился материал, кликните значок — вы поможете нам узнать, каким статьям и новостям следует отдавать предпочтение. Если вы хотите обсудить материал —не стесняйтесь оставлять свои комментарии : возможно, они будут полезны другим нашим читателям!





