
Пришёл, увидел, победил! (Veni, vidi, vici!)
Гай Юлий Цезарь о победе при Зеле над Фарнаком, сыном Митридата, 47 г. до н. э.
Введение
Машинное зрение (machine vision) – это обширный прикладной раздел междисциплинарной теории компьютерного зрения (computer vision), представляющий существенный потенциал для встраиваемых систем.Машинное зрение как инженерная дисциплина находится на стыке нескольких областей, таких как компьютерное зрение, встраиваемые системы, базы данных, машинное обучение.
Среди многочисленных областей применения наиболее обширные внедрения наблюдаются в области промышленности и военных разработок по следующим направлениям:
- системы визуального контроля и управления;
- системы безопасности;
- системы виртуальной и дополненной реальности;
- технические средства высокой степени автономности, от пилотажно-навигационных подсистем боевой информационно-управляющей системы (БИУС) до полностью автономных роботизированных технических средств.
Мониторинг контролируемого пространства связан с идентификацией в реальном времени значительного количества разнообразных объектов, их классификацией и своевременным принятием по ним решений, поэтому задача совершенствования аппаратно-программных средств для работы с высокоинтенсивными потоками видеоинформации является весьма актуальной.
Для встраиваемых систем реального времени, использующих машинное зрение для распознавания объектов, особое значение приобретают производительность и скорость реакции. Производительность системы может быть оценена по количеству обрабатываемых в единицу времени видеокадров, скорость реакции – по временной задержке между поступлением на приёмник видеокадра и моментом принятия решения по данным с него. Показатели производительности такой системы также достаточно наглядны – так, например, задержки изображения объекта относительно реального прототипа будут хорошо видны наблюдателю.
Разработанная в компании ЗАО «НПФ «ДОЛОМАНТ» высокопроизводительная гетерогенная вычислительная платформа (ВГВП) ГРИФОН [1] предназначена для решения задач с высокими требованиями к вычислительной мощности и большими объёмами анализируемой информации, она позволяет создавать высокопроизводительные БИУС, в том числе многоканальные системы обработки видео. В состав гетерогенной системы могут входить процессорные модули, графические ускорители, ускорители на основе ПЛИС, располагающиеся на межмодульной шине PCI Express. Для некоторых ресурсоёмких задач такое аппаратное решение может оказаться наилучшим, с точки зрения производительности, стоимости и гибкости [2].
Задачи компьютерного зрения предоставляют разработчикам большой простор для распараллеливания, например, входящие в состав вычислителей графические модули могут параллельно обрабатывать данные из нескольких видеопотоков, накладывать на один и тот же кадр различные фильтры, искать в кадре независимо друг от друга объекты различных типов и др. Структура потока данных в системе может существенно меняться на различных этапах обработки, от объёмных структурно-разнородных данных в разнообразных нестандартных форматах (видеопотоков от камер высокого разрешения) до небольших пакетов данных (сжатых на видеокарте кадров).
В гетерогенной системе при обработке каждого типа потока данных можно выбрать наиболее эффективную архитектуру. Например, для реализации ряда специальных прикладных алгоритмов или предварительной обработки нестандартных данных целесообразно использовать вычислитель на базе ПЛИС, для стандартной обработки видеопотоков – вычислители на базе графических процессоров, для решения задач контроля и принятия решений – вычислитель с центральным процессором.
Платформу ГРИФОН выгодно отличает от аналогов возможность построения на её базе параллельно-конвейерной системы за счёт поддержки между вычислителями соединений типа «точка–точка» через PCI Express-коммутатор. Богатый аппаратный состав платформы и гетерогенность её вычислительной среды позволяют достаточно эффективно и быстро организовать параллельно-конвейерную обработку. Идея использования гетерогенных вычислительных конвейеров заключается в выстраивании процесса обработки данных в цепочку. На каждом этапе такой цепочки (участке конвейера) с данными работает вычислитель с оптимальной для данного этапа аппаратной архитектурой. Своевременная загрузка конвейера новыми данными без накладных расходов на их пересылку позволяет организовать одновременную и слаженную работу всех вычислительных модулей.
Механизмы параллельно-конвейерной обработки являются признанным классическим методом повышения быстродействия систем обработки данных, и если структура данных и алгоритм позволяют распараллеливать задачу, это почти всегда повышает эффективность такой обработки.
Решение задачи компьютерного зрения
Постановка задачи
Рассмотрим возможность организации параллельно-конвейерной обработки данных на платформе ГРИФОН на примере системы обработки видео высокого разрешения. Постановку задачи можно сформулировать следующим образом – требуется:- в режиме реального времени принимать данные от двух камер разрешением 1920×1080;
- провести предварительную обработку кадров при приёме;
- применить к видеопотокам алгоритмы фильтрации и компьютерного зрения (поиск лиц, детектор движения, фильтр Собеля);
- отобразить полученный результат на мониторах;
- сжать видео кодеком MPEG-4;
- записать в режиме реального времени сжатое видео на жёсткий диск.
Состав вычислителя
Для решения поставленной задачи в состав гетерогенного вычислителя нами были включены:- модуль центрального процессора CPC510, работающий под управлением Linux Ubuntu 14.04;
- модуль ПЛИС FPU500 с мезонинным модулем ввода TB-FMCH-3GSDI2A;
- модуль графического процессора VIM556;
- модуль-носитель HDD-накопителя KIC550 (табл. 1).

Организация взаимодействия между модулями вычислителя
Последовательность операций, которые требуется провести над видеопотоками, можно организовать в виде независимо работающего конвейера. Видеопотоки удобно обрабатывать в независимо работающих параллельных конвейерах (рис. 1).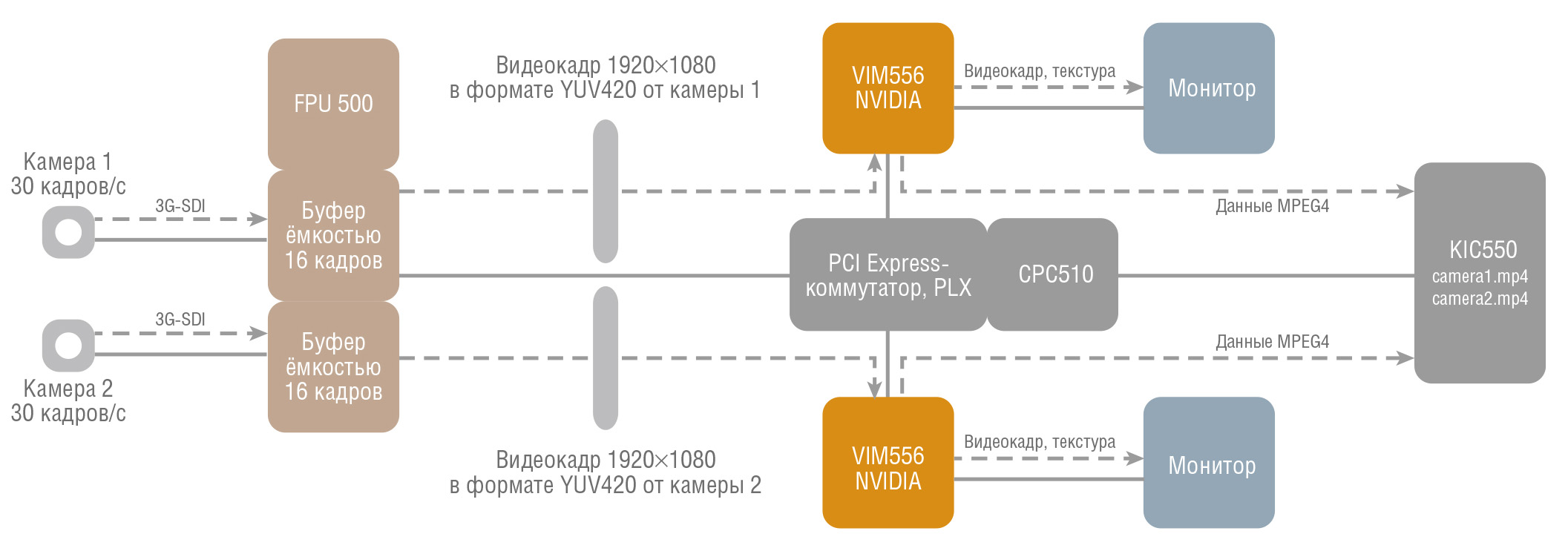
Условные обозначения:
3G-SDI – цифровой видеоинтерфейс для передачи телевидения высокой чёткости с прогрессивной развёрткой потоком до 2970 Мбит/с посредством одного коаксиального кабеля;
FPU500 – модуль реконфигурируемого процессора на базе ПЛИС Xilinx Virtex;
VIM556 – модуль графического процессора;
KIC550 – модуль-носитель HDD-накопителя.
Рис. 1. Общая схема системы обработки видео высокого разрешения на базе ГРИФОН
Каждый построенный для решения настоящей задачи конвейер включает в себя:
- блок управления входными данными, реализованный на модуле ПЛИС FPU500;
- графическую видеокарту VIM556;
- набор управляющих программных потоков, выполняющихся на процессорном модуле CPC510.
Реализацией алгоритмов компьютерного зрения в каждом видеопотоке занимаются вычислители VIM556, по одному на каждый поток. В их задачи входит проведение одной операции из списка: поиск лиц, детектирование движения, фильтрация Собеля. Результаты обработки видеоизображений вычислители сразу отображают на подключённых к ним мониторах, одновременно сжимая кадр встроенным в видеокарту аппаратным видеокодеком H.264 для подготовки его к отправке на жёсткий диск.
Управление конвейерами осуществляется приложением, выполняющимся на процессорном модуле CPC510. На обслуживание каждого конвейера в приложении выделено по 2 программных потока (нити), ответственных за контроль передачи данных и своевременное отображение кадров на графическом ускорителе.
Располагающийся на CPC510 коммутатор шины PCI Express Gen2 Switch PLX8624 и входящий в комплект поставки платформы ГРИФОН специальный драйвер обеспечивают устойчивую связь между всеми модулями системы.
В данном примере механизмы прямого межмодульного взаимодействия в режиме «каждый с каждым» позволяют высвободить ресурсы центрального процессора и снизить нагрузку на основной транспортный интерконнект по шине PCIe, что на практике даёт возможность минимизировать время обработки кадра всем конвейером.
Рассмотрим подробнее последовательности операций на основных этапах каждого конвейера.
Входной кадр разрешением 1920×1080 поступает через мезонин TB-FMCH-3GSDI2A на вход блока приёма данных ПЛИС. В блоке приёма изображение преобразуется на лету из формата YUV422 в более легковесный YUV420 и размещается в выделенной области DDR-памяти модуля FPU500, организованной в виде кольцевого буфера ёмкостью 16 кадров по 3 Мбайт. DDR-память модуля FPU500 доступна для чтения и записи через PCI Express всем вычислителям системы. Данные поступают в кольцевые буферы со скоростью 30 кадров в секунду. Отметим, что производительность системы такова, что кадры вычитываются из кольцевых буферов быстрее, чем они поступают в систему, и в каждом кольцевом буфере в произвольный момент времени находится не более одного кадра.
Записав кадр размером 3 Мбайт в DDR, FPU500 генерирует прерывание на шине, после чего переходит к ожиданию новых видеоданных. Весь алгоритм первичной обработки занимает не более 16 мкс.
Прерывание, полученное по PCI Express от FPU500, обрабатывается на CPC510 управляющим программным потоком, который выдаёт команду на копирование кадра из DDR-памяти FPU500 напрямую на VIM556 через коммутатор PLX8624. Получив новое изображение, видеокарта производит на нём одну из следующих операций на выбор: поиск лиц (рис. 2), детектирование движения (рис. 3) или фильтрацию Собеля (рис. 4).
")


Обработка изображений выполнена на CUDA с использованием функциональности библиотеки компьютерного зрения OpenCV: координаты лиц определяются методом Виолы-Джонса на основе каскадов Хаара [3, 4], при детектировании движения используются результаты выполнения алгоритма выделения фонового изображения с помощью распределений Гаусса [5], алгоритм выделения границ основывается на результатах применения к изображению оператора Собеля.
Результат обработки сразу отображается на подключённом к видеокарте мониторе и подвергается сжатию с помощью встроенного в VIM556 кодека H.264. Результат сжатия записывается в видеофайл в формате MPEG-4 на жёстком диске модуля KIC550.
Несмотря на широкие возможности библиотеки OpenCV, для вывода кадров с видеокарты сразу на дисплей применяются библиотеки OpenGL, GLEW и XLib. Кадры размещаются в областях памяти видеокарты типа «текстура», затем отрисовываются шейдерами на дисплее. Попытки использовать функции OpenCV для отображения приводили к излишним пересылкам кадров от VIM556 к CPC510 и обратно, что самым негативным образом сказывалось на производительности системы. По той же причине на CUDA пришлось реализовать функции рисования некоторых графических примитивов (прямоугольников). Контроль передаваемого по шине PCI Express трафика удобно производить с помощью PLX SDK, наглядно показывающего количество переданных и полученных байтов каждым устройством сети, а также скорости обмена.
Для сжатия видео встроенным в видеокарту кодеком используется NVIDIA Hardware Encoder SDK. Работа с кодеком построена таким образом, что его входные буферы, предназначенные для загрузки кадров, располагаются в локальной оперативной памяти VIM556 (рис. 5).

Любая излишняя пересылка данных по PCI Express, нарушающая принцип работы построенного конвейера, сразу приводила к простаиванию его элементов и резкому увеличению времени обработки кадра всей системой.
Производительность
Оценим основные характеристики построенных конвейеров: конвейерную задержку, пропускную способность, уровень загрузки ЦП.Оценка конвейерной задержки
В табл. 2 показаны длительности основных этапов цикла обработки кадра, как вместе, так и без механизма «точка–точка» (P2P).
Оценки были получены путём измерения длительности выполнения операций в управляющих потоках на процессорном модуле CPC510. Из приведённых данных видно, что реализованный в ГРИФОН механизм межмодульного взаимодействия позволяет значительно сократить величину конвейерной задержки. Действительно, при прямом обмене данными отпадает необходимость использовать процессорный модуль в качестве промежуточного звена передачи. Выигрыш от применяемого механизма «точка–точка» ещё более значителен, так как приведённые в таблице данные для режима «без PCIе P2P» не учитывают дополнительные временны́е затраты на пробуждение нитей на ЦП.
Величина задержки между моментом получения кадра 1920×1080 и его отображением на мониторе – менее 20 мс – подтверждает возможность построения на основе ГРИФОН систем видеотрансляции реального времени.
Оценка пропускной способности
Для оценки загруженности внутренней шины PCI Express нами использовался программный инструмент PLX SDK, показывающий потоки данных, проходящих через коммутатор PLX8624. Результаты мониторинга полностью соответствуют расчётным: из табл. 3 видно, что исходящие от FPU500 видеопотоки объёмом 89 Мбайт/с каждый поступают на соответствующие им графические модули VIM556.
Размер видеопотока согласуется с размером кадров (3 Мбайт) и скоростью их выдачи (30 кадров/с).
После сжатия кадры направляются на ЦП, что подтверждается наличием небольших потоков данных от графических ускорителей к ЦП (табл. 3).
Для сравнения в табл. 4 приведены объёмы потоков данных при работе ВГВП без механизма «точка–точка».

При отсутствии возможности прямого межмодульного обмена видеокадры сначала попадают на процессорный модуль и лишь затем перенаправляются на графические ускорители.
Общая загрузка шины PCI Express не превышает 10% от максимально возможного значения.
Загрузка центрального процессора
При решении задачи обработки видео с помощью построенного конвейера центральному процессору необходимо только координировать работу входящих в состав ГРИФОН элементов – непосредственной обработкой данных CPC510 не занимается. В его функции входят выдача управляющих команд модулям на приём/передачу данных, управление кодеком NVIDIA, управление выводом изображения на мониторы видеокарт, а также общий контроль работоспособности системы.Оценки загрузки центрального процессора в различных режимах мы проводили с помощью приложения htop, результаты измерений показаны в табл. 5.

Заключение
Преимущества использования гетерогенных конфигураций для решения ряда ресурсоёмких прикладных задач неоспоримы, а наращивание их применения является сегодня одним из трендов развития вычислительных систем.При этом оценка характеристик производительности систем с гетерогенной вычислительной средой является пока нетривиальной задачей, ввиду отсутствия готовых универсальных нагрузочных тестов и разнообразия способов решения прикладной задачи в гетерогенной вычислительной системе.
Продемонстрированный пример позволяет оценить наиболее критичные, с точки зрения аспектов быстродействия и производительности, характеристики гетерогенной системы при организации параллельно-конвейерной обработки данных в условиях высокой нагрузки. Так, разработанное для гетерогенной платформы ГРИФОН тестовое программное обеспечение позволило оценить ряд ключевых характеристик: конвейерную задержку, пропускную способность и загрузку центрального процессора в условиях достаточно серьёзной нагрузки.
Полученные результаты решения задачи обработки потокового видео высокого разрешения подтверждают на практике эффективность реализованных в платформе ГРИФОН подходов к построению параллельно-конвейерной обработки в гетерогенной среде и наглядно демонстрируют основные преимущества:
- каждый вычислитель задействован на своём участке конвейера и обрабатывает только те данные, для которых его архитектура оптимальна;
- параллельная работа различных звеньев цепи вычислительного конвейера;
- минимизация конвейерной задержки за счёт межмодульного взаимодействия в режиме «каждый с каждым» или «точка–точка»;
- разгрузка основного транспортного интерконнекта;
- существенное снижение нагрузки на центральный процессор и экономия его ресурсов для решения других задач.
Разработанная в ЗАО «НПФ «ДОЛОМАНТ» высокопроизводительная гетерогенная вычислительная платформа ГРИФОН позволяет строить и эффективно применять гетерогенные вычислительные конфигурации не только для систем машинного зрения, но и для самого широкого спектра прикладных задач, в том числе для создания подсистем БИУС, вне зависимости от предъявляемых требований к надёжности и производительности. ●
Литература
- Галаган П. Платформа ГРИФОН для решения задач встраиваемых систем специального назначения // Современные технологии автоматизации. – 2015. – № 4.
- M. Alawieh, M.n Kasparek, N. Franke, Hupfer. A High Perfomance FPGA-GPU-CPU Platform for a Real-Time Locating System // 23rd European Signal Processing Conference (EUSIPCO). – Fraunhofer Institute for Integrated Circuits IIS, Germany, 2015.
- P. Viola and M.J. Jones. Rapid Object Detection using a Boosted Cascade of Simple Features // Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR 2001). – 2001.
- P. Viola and M.J. Jones. Robust real-time face detection // International Journal of Computer Vision. – 2004. – Vol. 57. – No. 2.
- P. KaewTraKulPong and R. Bowden. An Improved Adaptive Background Mixture Model for Real-time Tracking with Shadow Detection // In Proc. 2nd European Workshop on Advanced Video Based Surveillance Systems. – Sept 2001.
Телефон: (495) 232-2033
Если вам понравился материал, кликните значок — вы поможете нам узнать, каким статьям и новостям следует отдавать предпочтение. Если вы хотите обсудить материал —не стесняйтесь оставлять свои комментарии : возможно, они будут полезны другим нашим читателям!



